Source Data Definition
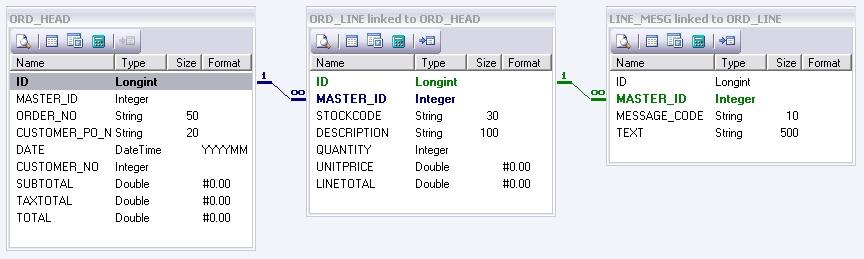
Source Data DefinitionThis data definition represents a list of orders and contains three datasets ORD_HEAD, ORD _LINE, and LINE_MESG. By the symbols next to the linking line you can determine the hierarchy and therefore which is the child dataset (the infinity sign is the child). In this case LINE_MESG is the child of ORD_LINE which is again the child of ORD_HEAD.
This data definition therefore contains a list of orders, each order having one or more lines, and each line having one or more messages. Lets pretend that there are 10 orders in total within the data definition - 10 ORD_HEAD records each with 5 ORD_LINE records, each with 2 LINE_MESG records.